
|
|
ResearchMy research lies at the intersection of computer vision and machine learning, particularly focused on the controllability of generative models across various modalities (image, video, 3D, 4D). I have broadly worked on foundation model post-training for visual grounding and audio reasoning, synthetic 3D and 4D physics interaction data generation, and emotional 3D animation of virtual humans with applications in VR-based human–computer interaction (HCI). Previously, I explored Bayesian optimization for multi-agent systems, robotics, and computer-aided engineering. ▸ Currently at Adobe Research London with Paul, Chun-Hao, Yulia, and Hyeonho, working on video foundation models.
/
/
/
/
/
|

|
Towards Reliable Human Evaluations in Gesture Generation: Insights from a Community-Driven State-of-the-Art BenchmarkRajmund Nagy, Hendric Voß, Thanh Hoang-Minh, Mihail Tsakov, Teodor Nikolov, Zeyi Zhang, Tenglong Ao, Sicheng Yang, Shaoli Huang, Yongkang Cheng, M. Hamza Mughal, Rishabh Dabral, Kiran Chhatre, Christian Theobalt, Libin Liu, Stefan Kopp, Rachel McDonnell, Michael Neff, Taras Kucherenko, Youngwoo Yoon, Gustav Eje Henter arXiv preprint, 2026 arxiv / website / video / code / We introduce a standard user-study protocol for evaluating speech-driven 3D gesture models and benchmark six methods on BEAT2. We release videos, code, and human ratings to support fair comparison. |

|
Spectrum: Learning 3D Texture-Aware Representations for Parsing Diverse Human Clothing and Body PartsKiran Chhatre, Christopher Peters, Srikrishna Karanam Association for the Advancement of Artificial Intelligence (AAAI), 2026 arxiv / website / poster / patent / Spectrum introduces a novel repurposing of an Image-to-Texture diffusion model for improved alignment with body parts and clothing, enabling detailed human parsing that handles diverse clothing types and complex poses across any number of humans in the scene. |

|
Synthetically Expressive: Evaluating gesture and voice for emotion and empathy in VR and 2D scenariosbest paper awardHaoyang Du, Kiran Chhatre, Christopher Peters, Brian Keegan, Rachel McDonnell, Cathy Ennis ACM International Conference on Intelligent Virtual Agents (IVA), 2025 arxiv / website / youtube / This work evaluates gesture and voice synthesis for conveying emotion and empathy in both VR and 2D scenarios, providing insights into the effectiveness of synthetic emotional expressions across different interaction modalities. |

|
Evaluation of Generative Models for Emotional 3D Animation Generation in VRKiran Chhatre, Renan Guarese, Andrii Matviienko, Christopher Peters Frontiers in Computer Science (Human-Media Interaction) & ACM SIGGRAPH I3D, 2025 arxiv / i3d workshop / website / video / supp. material / This work evaluates emotional 3D animation generative models within an immersive Virtual Reality environment, emphasizing user-centric metrics including emotional arousal realism, naturalness, enjoyment, diversity, face-body congruence, and interaction quality in real-time human-agent interaction scenarios. |
|
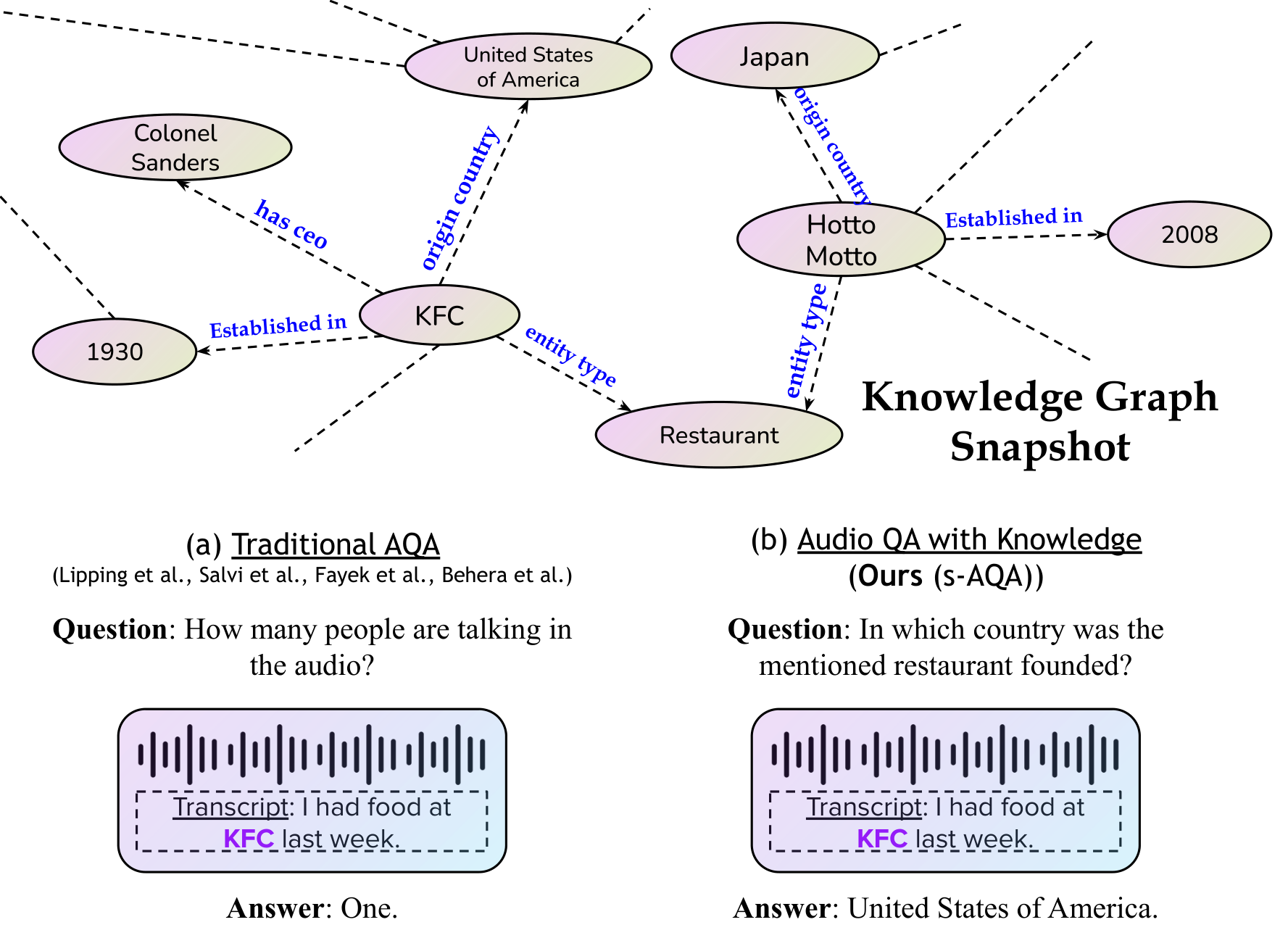
Audiopedia: Audio QA with KnowledgeoralAbhirama S. Penamakuri*, Kiran Chhatre*, Akshat Jain (* denotes equal contribution) IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025 arxiv / website / code / Audiopedia introduces a novel, knowledge-intensive audio question answering task and proposes a framework to enhance audio language models by integrating external knowledge. |

|
AMUSE: Emotional Speech-driven 3D Body Animation via Disentangled Latent DiffusionKiran Chhatre, Radek Daněček, Nikos Athanasiou, Giorgio Becherini, Christopher Peters, Michael J. Black, Timo Bolkart IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 arxiv / website / youtube / code / poster / x thread / AMUSE generates realistic emotional 3D body gestures directly from a speech sequence. It provides user control over the generated emotion by combining the driving speech with a different emotional audio. |

|
EMOTE: Emotional Speech-Driven Animation with Content-Emotion DisentanglementRadek Daněček, Kiran Chhatre, Shashank Tripathi, Yandong Wen, Michael J. Black, Timo Bolkart ACM SIGGRAPH Asia Conference Papers, 2023 arxiv / website / video / code / x thread / Given audio input and an emotion label, EMOTE generates an animated 3D head that has state-of-the-art lip synchronization while expressing the emotion. The method is trained from 2D video sequences using a novel video emotion loss and a mechanism to disentangle emotion from speech. |

|
BEAMBayesOpt: Parallel Bayesian Optimization of Agent-Based Transportation Simulationspecial mentionsKiran Chhatre, Sidney Feygin, Colin Sheppard, Rashid Waraich Springer Nature International Conference on Machine Learning, Optimization, and Data Science (LOD), 2022 paper / code / BEAM-integration / BEAMBayesOpt introduces a parallel Bayesian optimization approach with early stopping that autonomously calibrates hyperparameters in BEAM’s large-scale multi-agent transportation simulations and enables efficient surrogate modeling of complex scenarios. |

|
Spatio-temporal priors in 3D human motionAnna Deichler*, Kiran Chhatre*, Christopher Peters, Jonas Beskow (* denotes equal contribution) IEEE International Conference on Development and Learning (StEPP) workshop, 2021 arxiv / website / This workshop paper investigates spatial-temporal priors for 3D human motion synthesis by comparing graph convolutional networks and transformer architectures to capture dynamic joint dependencies. |

|
Rethinking Computer-Aided Architectural Design (CAAD) – From Generative Algorithms and Architectural Intelligence to Environmental Design and Ambient IntelligenceTodor Stojanovski, Hui Zhang, Emma Frid, Kiran Chhatre, Christopher Peters, Ivor Samuels, Paul Sanders, Jenni Partanen, Deborah Lefosse Springer Nature International Conference on Computer-Aided Architectural Design Futures (CAAD Futures), 2021 paper / This paper reviews the evolution of CAAD—from generative algorithms and BIM to current AI developments—and argues that integrating AI-driven ambient intelligence into digital design tools can transform architectural and urban design for smarter, more sustainable cities. |
Academic Services
Conference Reviewer: CVPR, NeurIPS, ICLR, AAAI, ICCV, SIGGRAPH, SIGGRAPH Asia, Eurographics, ISMAR, CoG, IVA |
Miscellaneous
EU Reports: MSCA ITN Clipe project |
|
Updated on: 2025-12-22 |
Thanks, Jon Barron! |